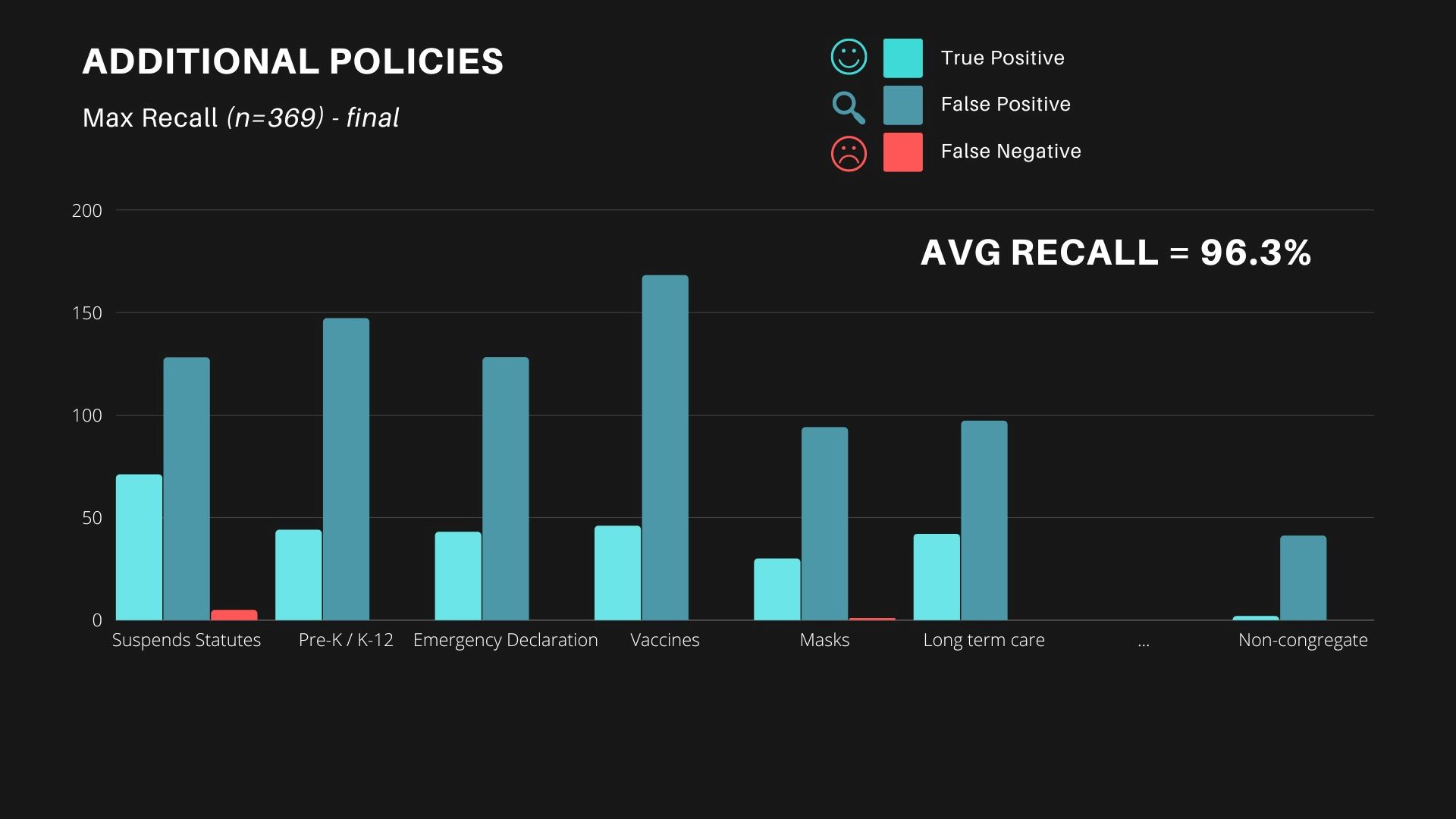
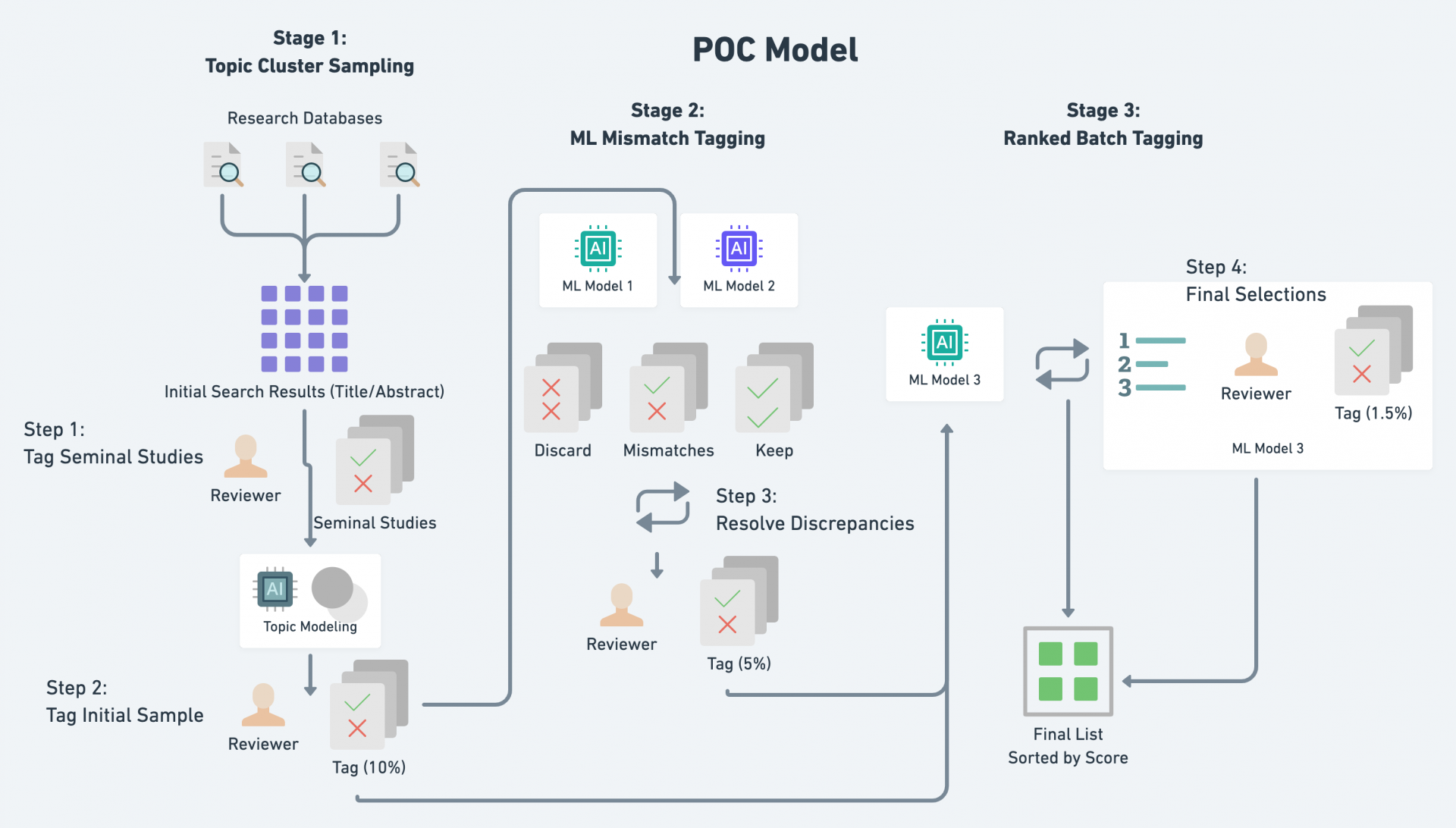
COVID-19 Policy Document Classification System (2020)
Goal:
To create an automated process to help CDC’s Covid Mitigation team analyze and categorize legislation documents more rapidly. The current process is entirely manual, and resulted in a backlog of thousands of unprocessed documents.
Summary:
The ETDAB team analyzed a trove of existing PDF legal documents along with the corresponding tags that were manually labeled in the previous process. Using this dataset as a starting point, the team built a pipeline that ingested PDF documents, scrapes all text using Optical Character Recognition, and tagged each document with the appropriate metadata. In addition, the team trained several custom neural network models for text classification using TensorFlow. Combined into an automated pipeline, the new system was able to process 17,000 untagged documents in under two weeks, saving approximately 298 days of manual labor.
Automated document scraping and metadata extraction was performed using open-source libraries in python scripts. Custom neural networks were trained locally using Google’s open-sourced TensorFlow framework. Once testing and training were completed, the entire process was bundled into two docker containers, one containing the trained TensorFlow models using TensorFlow Serve, and another with a flask-based REST API, which hosted the entire classification pipeline. This Docker-based architecture enabled management of dependencies and communication between APIs, making the project more efficient and enabling future implementations to be easily shifted to another hosting environment.